AST 抽象语法树
提起 AST 抽象语法树,大家可能并不感冒。但是提到它的使用场景,也许会让你大吃一惊。原来它一直在你左右与你相伴,而你却不知。
一、什么是抽象语法树
在计算机科学中,抽象语法树(abstract syntax tree 或者缩写为 AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。树上的每个节点都表示源代码中的一种结构。
之所以说语法是「抽象」的,是因为这里的语法并不会表示出真实语法中出现的每个细节。
二、使用场景
- JS 反编译,语法解析
- Babel 编译 ES6 语法
- 代码高亮
- 关键字匹配
- 作用域判断
- 代码压缩
三、AST Explorer
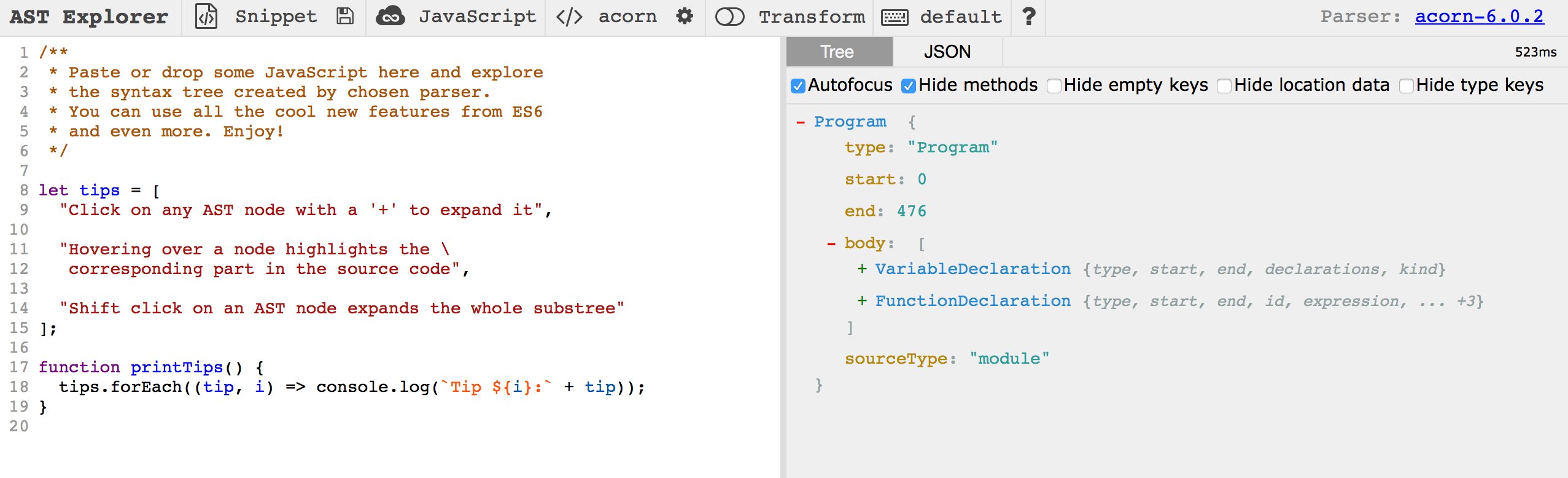
我们来看一个 ES6 的解释器,声明如下的代码:1
2
3let tips = [
"Jartto's AST Demo"
];
看看是如何解析的, JSON 格式如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41{
"type": "Program",
"start": 0,
"end": 38,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 37,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 36,
"id": {
"type": "Identifier",
"start": 4,
"end": 8,
"name": "tips"
},
"init": {
"type": "ArrayExpression",
"start": 11,
"end": 36,
"elements": [
{
"type": "Literal",
"start": 15,
"end": 34,
"value": "Jartto's AST Demo",
"raw": "\"Jartto's AST Demo\""
}
]
}
}
],
"kind": "let"
}
],
"sourceType": "module"
}
而它的语法树大概如此:
每个结构都看的清清楚楚,这时候我们会发现,这和 Dom 树真的差不了多少。再来看一个例子:1
(1+2)*3
AST Tree: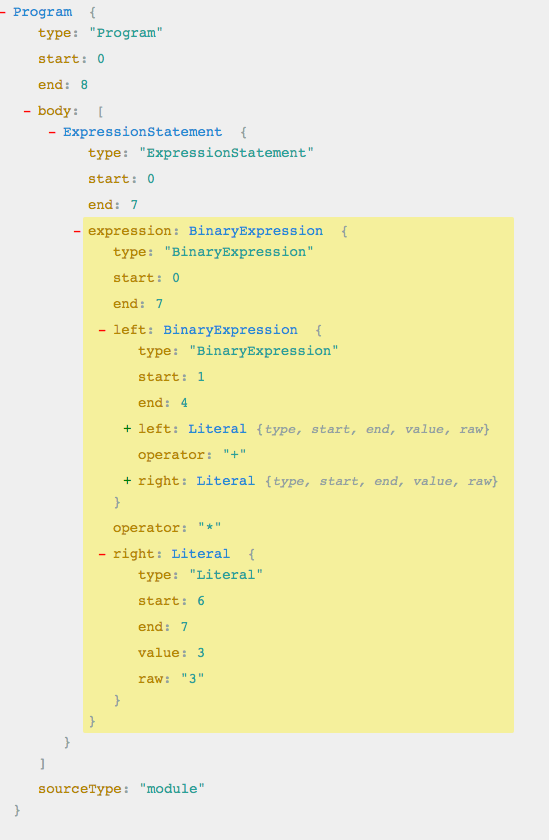
我们删掉括号,看看规则是如何变化的?JSON 格式会一目了然:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46{
"type": "Program",
"start": 0,
"end": 6,
"body": [
{
"type": "ExpressionStatement",
"start": 0,
"end": 5,
"expression": {
"type": "BinaryExpression",
"start": 0,
"end": 5,
"left": {
"type": "Literal",
"start": 0,
"end": 1,
"value": 1,
"raw": "1"
},
"operator": "+",
"right": {
"type": "BinaryExpression",
"start": 2,
"end": 5,
"left": {
"type": "Literal",
"start": 2,
"end": 3,
"value": 2,
"raw": "2"
},
"operator": "*",
"right": {
"type": "Literal",
"start": 4,
"end": 5,
"value": 3,
"raw": "3"
}
}
}
}
],
"sourceType": "module"
}
可以看出来,(1+2)*3 和 1+2*3,语法树是有差别的:
1.在确定类型为 ExpressionStatement 后,它会按照代码执行的先后顺序,将表达式 BinaryExpression 分为 Left,operator 和 right 三块;
2.每块标明了类型,起止位置,值等信息;
3.操作符类型;
再来看看我们最常用的箭头函数:1
2
3const mytest = (a,b) => {
return a+b;
}
JSON 格式如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79{
"type": "Program",
"start": 0,
"end": 42,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 41,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 41,
"id": {
"type": "Identifier",
"start": 6,
"end": 12,
"name": "mytest"
},
"init": {
"type": "ArrowFunctionExpression",
"start": 15,
"end": 41,
"id": null,
"expression": false,
"generator": false,
"params": [
{
"type": "Identifier",
"start": 16,
"end": 17,
"name": "a"
},
{
"type": "Identifier",
"start": 18,
"end": 19,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 24,
"end": 41,
"body": [
{
"type": "ReturnStatement",
"start": 28,
"end": 39,
"argument": {
"type": "BinaryExpression",
"start": 35,
"end": 38,
"left": {
"type": "Identifier",
"start": 35,
"end": 36,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 37,
"end": 38,
"name": "b"
}
}
}
]
}
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
AST Tree 结构如下图: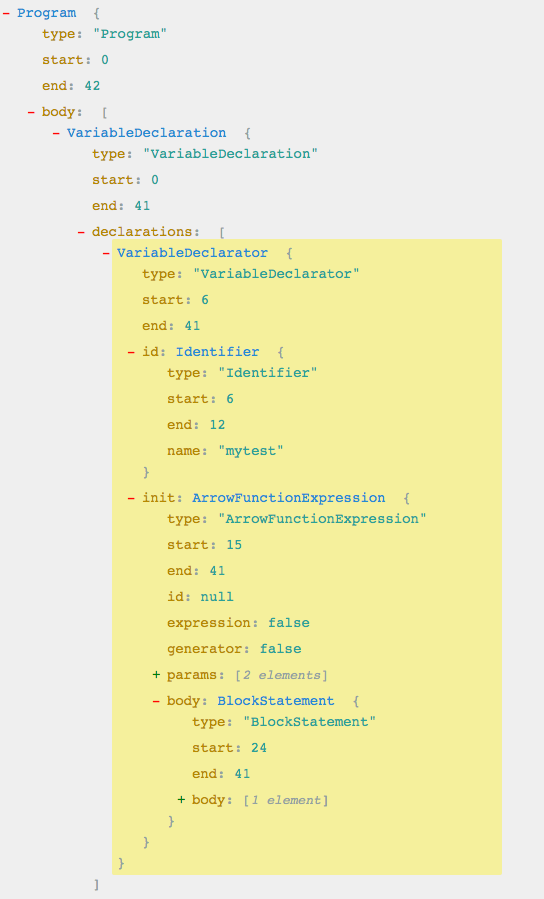
我们注意到了,增加了几个新的字眼:
ArrowFunctionExpressionBlockStatementReturnStatement
到这里,其实我们已经慢慢明白了:
抽象语法树其实就是将一类标签转化成通用标识符,从而结构出的一个类似于树形结构的语法树。
四、深入原理
可视化的工具可以让我们迅速有感官认识,那么具体内部是如何实现的呢?
继续使用上文的例子:1
Function getAST(){}
JSON 也很简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28{
"type": "Program",
"start": 0,
"end": 19,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 19,
"id": {
"type": "Identifier",
"start": 9,
"end": 15,
"name": "getAST"
},
"expression": false,
"generator": false,
"params": [],
"body": {
"type": "BlockStatement",
"start": 17,
"end": 19,
"body": []
}
}
],
"sourceType": "module"
}
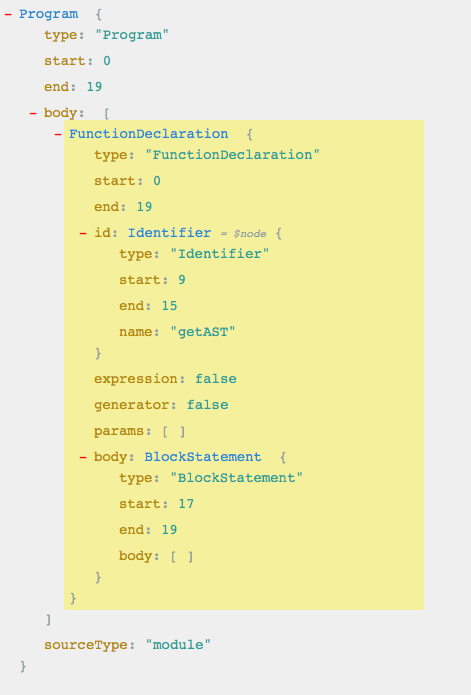
怀着好奇的心态,我们来模拟一下用代码实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19const esprima = require('esprima'); //解析js的语法的包
const estraverse = require('estraverse'); //遍历树的包
const escodegen = require('escodegen'); //生成新的树的包
let code = `function getAST(){}`;
//解析js的语法
let tree = esprima.parseScript(code);
//遍历树
estraverse.traverse(tree, {
enter(node) {
console.log('enter: ' + node.type);
},
leave(node) {
console.log('leave: ' + node.type);
}
});
//生成新的树
let r = escodegen.generate(tree);
console.log(r);
运行后,输出:1
2
3
4
5
6
7
8
9
10enter: Program
enter: FunctionDeclaration
enter: Identifier
leave: Identifier
enter: BlockStatement
leave: BlockStatement
leave: FunctionDeclaration
leave: Program
function getAST() {
}
我们看到了遍历语法树的过程,这里应该是深度优先遍历。
稍作修改,我们来改变函数的名字 getAST => Jartto:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19const esprima = require('esprima'); //解析js的语法的包
const estraverse = require('estraverse'); //遍历树的包
const escodegen = require('escodegen'); //生成新的树的包
let code = `function getAST(){}`;
//解析js的语法
let tree = esprima.parseScript(code);
//遍历树
estraverse.traverse(tree, {
enter(node) {
console.log('enter: ' + node.type);
if (node.type === 'Identifier') {
node.name = 'Jartto';
}
}
});
//生成新的树
let r = escodegen.generate(tree);
console.log(r);
运行后,输出:1
2
3
4
5
6enter: Program
enter: FunctionDeclaration
enter: Identifier
enter: BlockStatement
function Jartto() {
}
可以看到,在我们的干预下,输出的结果发生了变化,方法名编译后方法名变成了 Jartto。
这就是抽象语法树的强大之处,本质上通过编译,我们可以去改变任何输出结果。
补充一点:关于 node 类型,全集大致如下:1
(parameter) node: Identifier | SimpleLiteral | RegExpLiteral | Program | FunctionDeclaration | FunctionExpression | ArrowFunctionExpression | SwitchCase | CatchClause | VariableDeclarator | ExpressionStatement | BlockStatement | EmptyStatement | DebuggerStatement | WithStatement | ReturnStatement | LabeledStatement | BreakStatement | ContinueStatement | IfStatement | SwitchStatement | ThrowStatement | TryStatement | WhileStatement | DoWhileStatement | ForStatement | ForInStatement | ForOfStatement | VariableDeclaration | ClassDeclaration | ThisExpression | ArrayExpression | ObjectExpression | YieldExpression | UnaryExpression | UpdateExpression | BinaryExpression | AssignmentExpression | LogicalExpression | MemberExpression | ConditionalExpression | SimpleCallExpression | NewExpression | SequenceExpression | TemplateLiteral | TaggedTemplateExpression | ClassExpression | MetaProperty | AwaitExpression | Property | AssignmentProperty | Super | TemplateElement | SpreadElement | ObjectPattern | ArrayPattern | RestElement | AssignmentPattern | ClassBody | MethodDefinition | ImportDeclaration | ExportNamedDeclaration | ExportDefaultDeclaration | ExportAllDeclaration | ImportSpecifier | ImportDefaultSpecifier | ImportNamespaceSpecifier | ExportSpecifier
说到这里,聪明的你,可能想到了 Babel,想到了 js 混淆,想到了更多背后的东西。接下来,我们要介绍介绍 Babel 是如何将 ES6 转成 ES5 的。
五、关于 Babel
由于 ES6 的兼容问题,很多情况下,我们都在使用 Babel 插件来进行编译,那么有没有想过 Babel 是如何工作的呢?先来看看:1
let sum = (a, b)=>{return a+b};
AST 大概如此: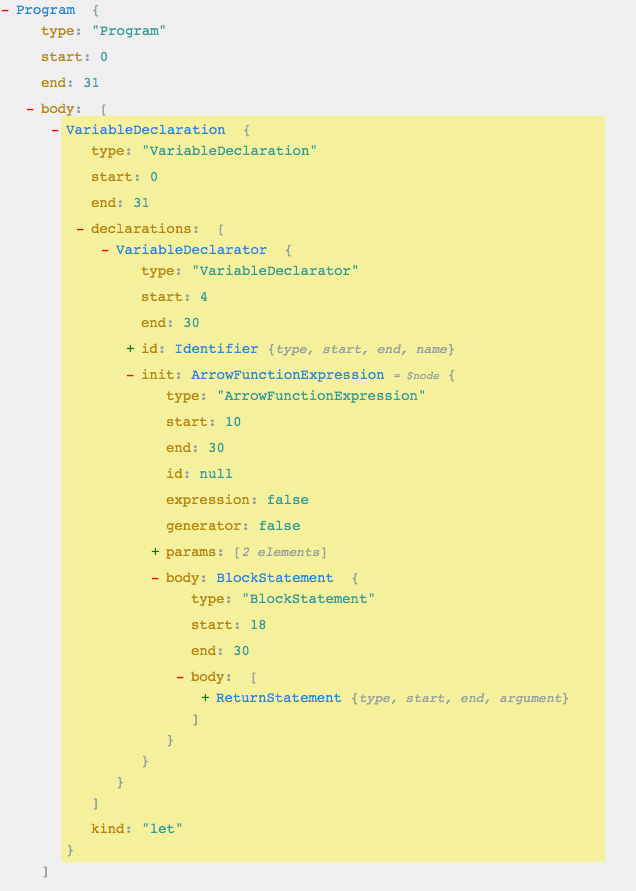
JSON 格式可能会看的清楚些:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79{
"type": "Program",
"start": 0,
"end": 31,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 31,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 30,
"id": {
"type": "Identifier",
"start": 4,
"end": 7,
"name": "sum"
},
"init": {
"type": "ArrowFunctionExpression",
"start": 10,
"end": 30,
"id": null,
"expression": false,
"generator": false,
"params": [
{
"type": "Identifier",
"start": 11,
"end": 12,
"name": "a"
},
{
"type": "Identifier",
"start": 14,
"end": 15,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 18,
"end": 30,
"body": [
{
"type": "ReturnStatement",
"start": 19,
"end": 29,
"argument": {
"type": "BinaryExpression",
"start": 26,
"end": 29,
"left": {
"type": "Identifier",
"start": 26,
"end": 27,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 28,
"end": 29,
"name": "b"
}
}
}
]
}
}
}
],
"kind": "let"
}
],
"sourceType": "module"
}
结构大概如此,那我们再用代码模拟一下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23const babel = require('babel-core'); //babel核心解析库
const t = require('babel-types'); //babel类型转化库
let code = `let sum = (a, b)=>{return a+b}`;
let ArrowPlugins = {
//访问者模式
visitor: {
//捕获匹配的API
ArrowFunctionExpression(path) {
let { node } = path;
let body = node.body;
let params = node.params;
let r = t.functionExpression(null, params, body, false, false);
path.replaceWith(r);
}
}
}
let d = babel.transform(code, {
plugins: [
ArrowPlugins
]
})
console.log(d.code);
记得安装 babel-core,babel-types 这俩插件,之后运行 babel.js,我们看到了这样的输出:1
2
3let sum = function (a, b) {
return a + b;
};
这里,我们完美的将箭头函数转换成了标准函数。
那么问题又来了,如果是简写呢,像这样,还能正常编译吗?1
let sum = (a, b)=>a+b
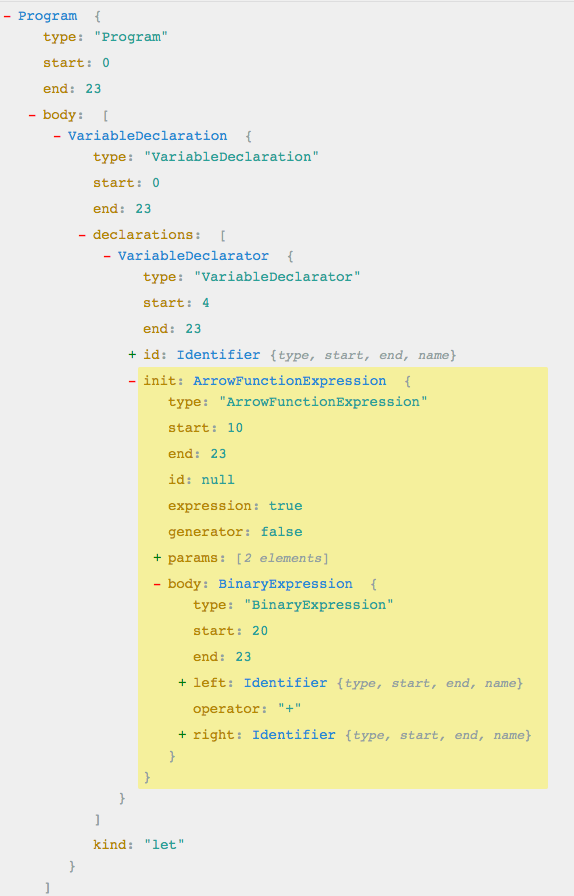
Body 部分的结构发生了变化,所以,我们的 babel.js 运行就会报错了。1
TypeError: unknown: Property body of FunctionExpression expected node to be of a type ["BlockStatement"] but instead got "BinaryExpression"
意思很明了,我们的 body 类型变成 BinaryExpression 不再是 BlockStatement,所以需要做一些修改:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27const babel = require('babel-core'); //babel核心解析库
const t = require('babel-types'); //babel类型转化库
let code = `let sum = (a, b)=> a+b`;
let ArrowPlugins = {
//访问者模式
visitor: {
//捕获匹配的API
ArrowFunctionExpression(path) {
let { node } = path;
let params = node.params;
let body = node.body;
if(!t.isBlockStatement(body)){
let returnStatement = t.returnStatement(body);
body = t.blockStatement([returnStatement]);
}
let r = t.functionExpression(null, params, body, false, false);
path.replaceWith(r);
}
}
}
let d = babel.transform(code, {
plugins: [
ArrowPlugins
]
})
console.log(d.code);
看看输出结果:1
2
3let sum = function (a, b) {
return a + b;
};
看起来不错,堪称完美~
六、深入 Babel
当然,上文我们简单演示了 Babel 是如何来编译代码的,但是并非简单如此。
Babel 使用一个基于 ESTree 并修改过的 AST,它的内核说明文档可以在这里找到。
正如我们上面示例代码一样,Babel 的三个主要处理步骤分别是: 解析(parse),转换(transform),生成(generate)。
1.解析(parse):解析步骤接收代码并输出 AST。 这个步骤分为两个阶段:词法分析 Lexical Analysis 和语法分析Syntactic Analysis。
词法分析:词法分析阶段把字符串形式的代码转换为令牌(
tokens) 流。你可以把令牌看作是一个扁平的语法片段数组:1
n * n;
例如上面的代码片段,解析结果如下:
1
2
3
4
5
6[
{ type: { ... }, value: "n", start: 0, end: 1, loc: { ... } },
{ type: { ... }, value: "*", start: 2, end: 3, loc: { ... } },
{ type: { ... }, value: "n", start: 4, end: 5, loc: { ... } },
...
]每一个
type有一组属性来描述该令牌,和AST节点一样它们也有start,end,loc属性:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{
type: {
label: 'name',
keyword: undefined,
beforeExpr: false,
startsExpr: true,
rightAssociative: false,
isLoop: false,
isAssign: false,
prefix: false,
postfix: false,
binop: null,
updateContext: null
},
...
}语法分析:语法分析阶段会把一个令牌流转换成
AST的形式。 这个阶段会使用令牌中的信息把它们转换成一个AST的表述结构,这样更易于后续的操作。
2.转换(transform):接收 AST 并对其进行遍历,在此过程中对节点进行添加、更新及移除等操作。 这是 Babel 或是其他编译器中最复杂的过程,同时也是插件将要介入工作的部分。
3.生成(generate):代码生成步骤把最终(经过一系列转换之后)的 AST 转换成字符串形式的代码,同时还会创建源码映射(source maps)。
代码生成其实很简单:深度优先遍历整个 AST,然后构建可以表示转换后代码的字符串。
了解这这些过程,我们回头再来参悟一下之前的示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23const babel = require('babel-core'); //babel核心解析库
const t = require('babel-types'); //babel类型转化库
let code = `let sum = (a, b)=>{return a+b}`;
let ArrowPlugins = {
//访问者模式
visitor: {
//捕获匹配的API
ArrowFunctionExpression(path) {
let { node } = path;
let body = node.body;
let params = node.params;
let r = t.functionExpression(null, params, body, false, false);
path.replaceWith(r);
}
}
}
let d = babel.transform(code, {
plugins: [
ArrowPlugins
]
})
console.log(d.code);
是不是发现突然简单易懂了。
七、关于遍历
想要转换 AST 你需要进行递归的树形遍历。
比方说我们有一个 FunctionDeclaration 类型。它有几个属性:id,params,和 body,每一个都有一些内嵌节点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29{
type: "FunctionDeclaration",
id: {
type: "Identifier",
name: "square"
},
params: [{
type: "Identifier",
name: "n"
}],
body: {
type: "BlockStatement",
body: [{
type: "ReturnStatement",
argument: {
type: "BinaryExpression",
operator: "*",
left: {
type: "Identifier",
name: "n"
},
right: {
type: "Identifier",
name: "n"
}
}
}]
}
}
按照上面的代码结构,我们来说一下具体流程:
1.首先我们从 FunctionDeclaration 开始并且我们知道它的内部属性(即:id,params,body),所以我们依次访问每一个属性及它们的子节点;
2.然后我们来到 id,它是一个 Identifier。Identifier 没有任何子节点属性,所以我们继续;
3.紧接着是 params,由于它是一个数组节点所以我们访问其中的每一个,它们都是 Identifier 类型的单一节点,然后我们继续;
4.此时我们来到了 body,这是一个 BlockStatement 并且也有一个 body 节点,而且也是一个数组节点,我们深入访问其中的每一个;
5.这里唯一的一个属性是 ReturnStatement 节点,它有一个 argument,我们访问 argument 就找到了 BinaryExpression;
6.BinaryExpression 有一个 operator,一个 left,和一个 right。 Operator 不是一个节点,它只是一个值。因此我们不用继续向内遍历,我们只需要访问 left 和 right。
Babel 的转换步骤基本都是是这样的遍历过程。
八、具体语法树
看到抽象语法树,我们脑海中会出现这样一个疑问:有没有具体语法树呢?
和抽象语法树相对的是具体语法树(通常称作分析树)。一般的,在源代码的翻译和编译过程中,语法分析器创建出分析树。一旦AST 被创建出来,在后续的处理过程中,比如语义分析阶段,会添加一些信息。
