抓取网页生成 PDF
看到自己喜欢的在线文档,是不是总想保存下来慢慢学习。可是苦于没有现成的工具,这里我来介绍两个 JS 类库,只需要简单封装一下,从此想抓哪里抓哪里。
一、使用 Phantomjs
1.简单使用1
2
3
4
5
6
7
8
9
10
11
12
13
14const phantom = require('phantom');
(async function() {
const instance = await phantom.create();
const page = await instance.createPage();
await page.on('onResourceRequested', function(requestData) {
console.info('Requesting', requestData.url);
});
const status = await page.open('http://jartto.wang');
await page.render('jarttoTest.pdf');
await instance.exit();
})();
上面是一个完整的示例,我们来看看最核心的部分,不妨放大一下:1
2
3
4
5
6
7
8
9
10
11
12page.open(address, function (status) {
if (status !== 'success') {
// --- Error opening the webpage ---
console.log('Unable to load the address!');
} else {
// --- Keep Looping Until Render Completes ---
window.setTimeout(function () {
page.render(output);
phantom.exit();
}, 200);
}
});
嗯,结合起来,就完美了。下面就是最佳实践:1
2
3
4
5
6
7
8
9
10
11var page = require('webpage').create();
page.open('http://jartto.wang', function(status) {
setTimeout(function() {
if ( status === 'success' ) {
page.render('test.png');
phantom.exit();
} else {
console.log('Page failed to load.');
}
}, 200);
});
因为 open 操作会有响应时间,所以需要使用 setTimeout 来确保流程。
这里需要额外补充一点,如果需要检测 UA,那么你需要这么使用:1
2
3
4
5
6
7var page = require('webpage').create();
page.userAgent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36';
page.open('https://securelearning.in', function() {
page.render('image.png');
phantom.exit();
});
这里就不再细说了,更多细节可以查看 Demo。
二、使用 Puppeteer
既然 Phantomjs 这么好用,为啥还要了解 Puppeteer ?
提到这个问题,我们不得不来说一下 Puppeteer 强大的官方背景:Puppeteer(木偶) 英[ˌpʌpɪˈtɪə(r)],美[ˌpʌpɪˈtɪr],是 Google Chrome 团队官方的无界面 (Headless)Chrome 工具。所以不管从以后的发展还是完整性方面,Puppeteer 都是我们的首选。
那么,Puppeteer 能用来干啥,有哪些功能:
- 生成页面的截图和
PDF - 爬取网站内容
- 模拟登陆、自动提交表单,
UI测试,键盘输入等 - 使用最新的
JavaScript和浏览器功能,直接在最新版本的Chrome中运行测试。 - 捕获网站的时间线跟踪,以帮助诊断性能问题
- 测试
Chrome扩展程序
说了这么多,让我们快速开始,迅速的体验一把。
1.安装1
npm i puppeteer
2.注意事项
安装并不会那么顺利,因为要依赖 Chromium ,所以你可能会遇到这样的异常。
Note: When you install Puppeteer, it downloads a recent version of Chromium (~170MB Mac, ~282MB Linux, ~280MB Win) that is guaranteed to work with the API. To skip the download, see Environment variables.
正确姿势:1
2
3
4
5set PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=1
npm i puppeteer
# 或者忽略依赖脚本安装 jartto's demo
npm i --save puppeteer --ignore-scripts
如果不能翻墙下载,那么就手动去官网下载 Chromium 吧。当然,坑远不止这些,感兴趣的童鞋可以戳这里 Puppeteer 异常处理。
3.下载核心包1
npm i puppeteer-core
从 1.7 版本开始发布 puppeteer-core ,他默认不会下载 Chromium 。puppeteer-core 使用已安装的浏览器 或远程浏览器。具体可以查看官网文档 puppeteer vs puppeteer-core.
4.示例
生成网站快照:1
2
3
4
5
6
7
8
9
10const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('http://jartto.wang');
await page.screenshot({path: 'blog.png'});
await browser.close();
})();
通过网站地址,生成 pdf:1
2
3
4
5
6
7
8
9
10const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md#pdf', {waitUntil: 'networkidle2'});
await page.pdf({path: 'jartto.pdf', format: 'A4'});
await browser.close();
})();
设置视口:1
await page.setViewport({width: 1024, height: 880});
设置 cookie:1
2
3
4
5
6
7
8
9const COOKS =[
{
'domain': 'jartto.wang',
'name': 'user',
'value': 'jartto',
}
]
await page.setCookie(...COOKS);
模拟设备 iphonex 来生成截图:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18const devices = require('puppeteer/DeviceDescriptors');
const puppeteer = require('puppeteer');
(async () => {
//创建浏览器示例对象
const browser = await puppeteer.launch({
executablePath: 'chromium/Chromium.app/Contents/MacOS/Chromium',
headless: true
});
// 通过浏览器实例 Browser 对象创建页面 Page 对象
const page = await browser.newPage();
await page.emulate(devices['iPhone X']);
await page.goto('http://jartto.wang');
await page.screenshot({path: 'temp/iphonex.png'});
await browser.close();
})().catch(error => console.log('error: ', error.message));
如果是本地的 chromium ,记得配置 executablePath: ‘chromium/Chromium.app/Contents/MacOS/Chromium’。
更有趣的事情是,我们可以搜索一些关键字来生成快照,譬如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22const devices = require('puppeteer/DeviceDescriptors')
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
executablePath: 'chromium/Chromium.app/Contents/MacOS/Chromium',
headless: true
});
const page = await browser.newPage();
await page.emulate(devices['iPhone X']);
await page.goto('https://www.baidu.com/');
// 输入框 id,搜索关键字 jartto
await page.type('#index-kw', 'jartto');
// 模拟点击提交按钮
await page.click('#index-bn');
// 跳转等待时间
await page.waitForNavigation({ timeout: 3000 });
await page.screenshot({path: 'temp/search.png'});
await browser.close();
})().catch(error => console.log('error: ', error.message));
执行上面的代码,将会打开百度搜索引擎,同时搜索关键字 jartto,跳转完成后进行截屏,保存成图片。核心代码:1
2
3
4
5
6// 输入框 id,搜索关键字 jartto
await page.type('#index-kw', 'jartto');
// 模拟点击提交按钮
await page.click('#index-bn');
// 跳转等待时间
await page.waitForNavigation({ timeout: 3000 });
一定要找准对应元素的 id,我们可以使用 chrome 开发者工具切换手机模式查看元素。
实际效果一览,左图为 blog 快照,右图为搜索跳转快照:
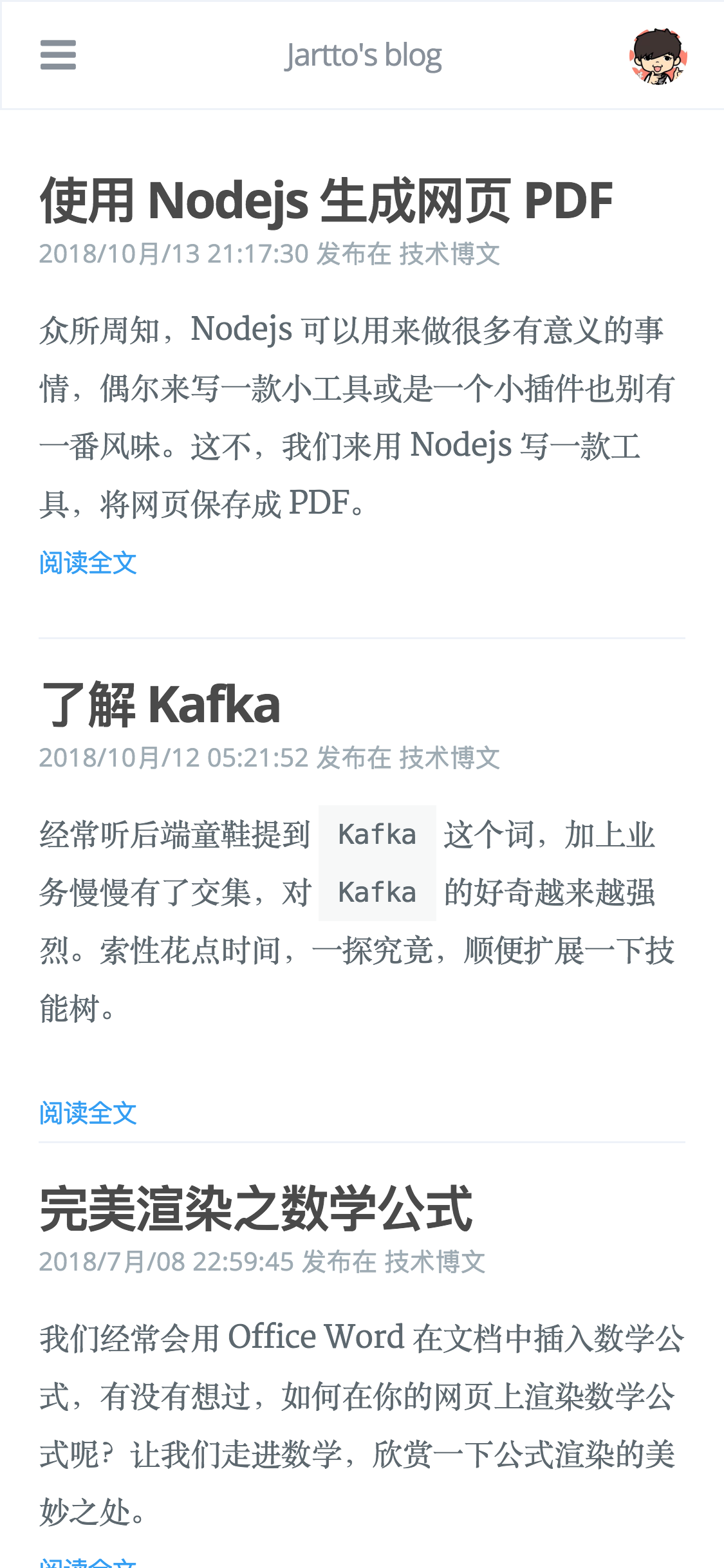
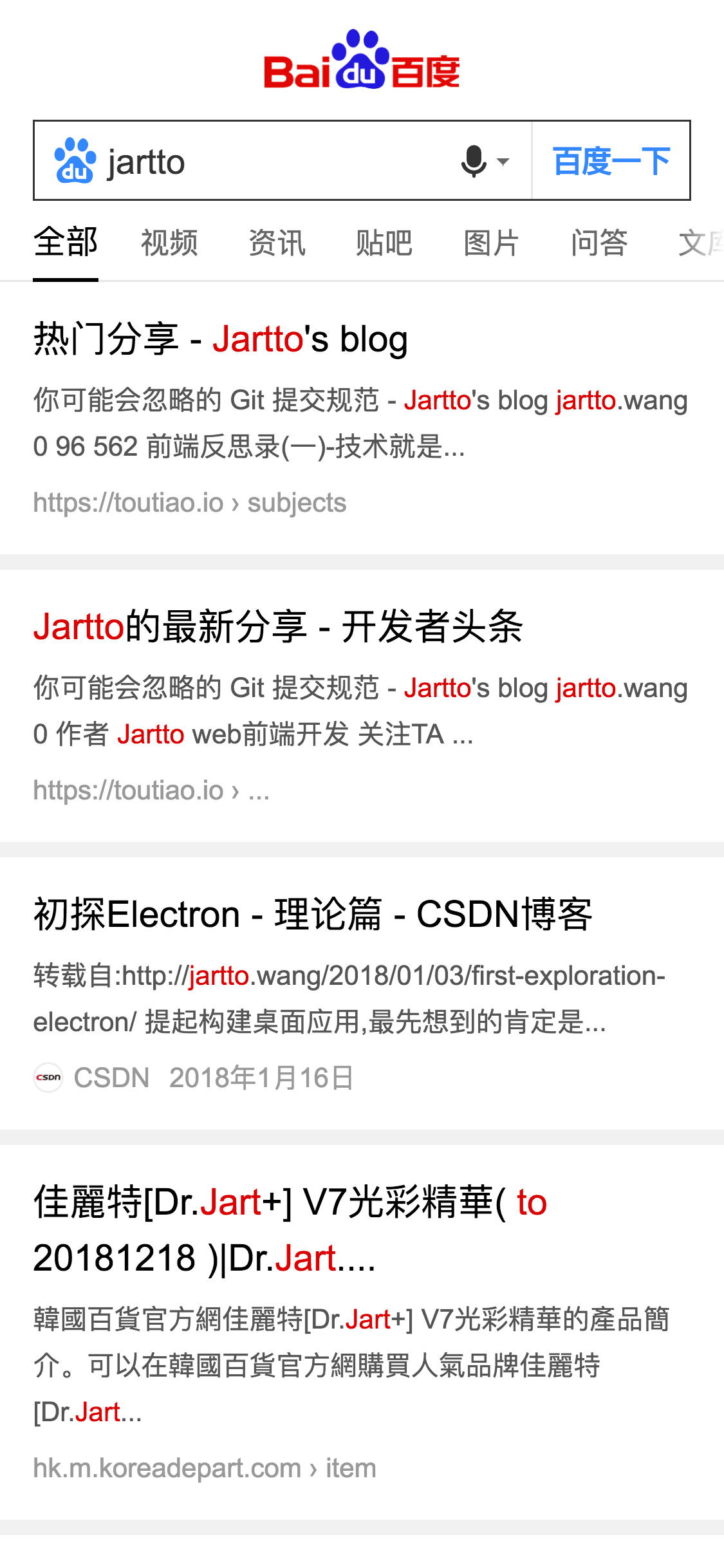
如果觉得例子还不够,这里有个在线演示,以及我自己写的 Demo。
5.相关资源
学习资源总是很多,由浅入深的学习将会事半功倍,下面我稍微整理一下。
- 第一阶段
- 第二阶段
- 第三阶段
循序渐进的开始你的学习旅程吧。
三、总结
文章提供了两种方式,在线抓取 URL 生成 PDF,当然插件的功能并不简单如此,你还可以做更多有趣的事情。嗯,慢慢摸索、积累,相信我,总有一天你会用上的。
