了解 Kafka
经常听后端童鞋提到 Kafka ,加上业务慢慢有了交集,对 Kafka 的好奇越来越强烈。索性花点时间,一探究竟,顺便扩展一下技能树。
一、Kafka 是什么?
Kafka 是分布式发布-订阅消息系统。它最初由 LinkedIn 公司开发,之后成为 Apache 项目的一部分。Kafka 是一个分布式的,可划分的,冗余备份的持久性的日志服务。
Kafka 是用于构建实时数据管道和流应用程序。具有横向扩展,容错,wicked fast(变态快)等优点。
二、简单理解
直接去解释概念可能比较枯燥,不如先委婉的理解一下。
举个例子,生产者消费者,生产者生产鸡蛋,消费者消费鸡蛋,生产者生产一个鸡蛋,消费者就消费一个鸡蛋,假设消费者消费鸡蛋的时候噎住了(系统宕机了),生产者还在生产鸡蛋,那新生产的鸡蛋就丢失了。
或者另一种情况:生产者很强劲(大交易量的情况),生产者 1 秒钟生产 100 个鸡蛋,消费者 1 秒钟只能吃 50 个鸡蛋,那要不了一会,消费者就吃不消了(消息堵塞,最终导致系统超时),消费者拒绝再吃了,「鸡蛋」又丢失了。
这个时候我们放个篮子在它们中间,生产出来的鸡蛋都放到篮子里,消费者去篮子里拿鸡蛋,这样鸡蛋就不会丢失了,都在篮子里,而这个篮子就是Kafka。
鸡蛋其实就是「数据流」,系统之间的交互都是通过「数据流」来传输的,也称为报文,也叫「消息」。消息队列满了,其实就是篮子满了,「鸡蛋」放不下了,那赶紧多放几个篮子,其实就是 Kafka 的扩容。
综上所述,Kafka 的概念就很好理解了,它就是那个「篮子」。
三、使用场景
通过简单形象的比喻,相信很多童鞋都大概了解 Kafka 是怎么一回事了。
那么我们要不要放「篮子」,以及什么情况我们需要去放这个「篮子」?
1.消息系统
对于一些常规的消息系统,Kafka 是个不错的选择。
2.检测网站活性Kafka 可以作为「网站活性跟踪」的最佳工具。可以将网页/用户操作等信息发送到 Kafka 中。并实时监控,或者离线统计分析等。
3.日志系统Kafka 的特性决定它非常适合作为「日志收集中心」;
kafka是一个分布式消息队列。一般在架构设计中起到解耦、削峰、异步处理的作用。
四、重要概念
- Producers:生产者,就是它来生产「鸡蛋」的。
- Consumers:消费者,生出的「鸡蛋」它来消费。
- topic:你把它理解为标签,生产者每生产出来一个鸡蛋就贴上一个标签(topic),消费者可不是谁生产的「鸡蛋」都吃的,这样不同的生产者生产出来的「鸡蛋」,消费者就可以选择性的吃了。
- broker:就是篮子喽。
除了上面几个概念,还有一个也非常重要,那就是 zookeeper。
1) Producer 端使用 zookeeper 用来发现 broker 列表,以及和 Topic 下每个 partition leader 建立 socket 连接并发送消息。
2) Broker 端使用 zookeeper 用来注册 broker 信息,已经监测 partition leader 存活性。
3) Consumer 端使用 zookeeper 用来注册 consumer 信息,其中包括 consumer 消费的 partition 列表等,同时也用来发现 broker 列表,并和 partition leader 建立 socket 连接,并获取消息。
五、Kafka 数据流
看完「鸡蛋」,「篮子」,我们逐渐清晰了,可这他娘的 zookeeper 又出来搅合了,是不是有点懵比了?不要着急,看看下面这张图,也许你就了然于胸了。
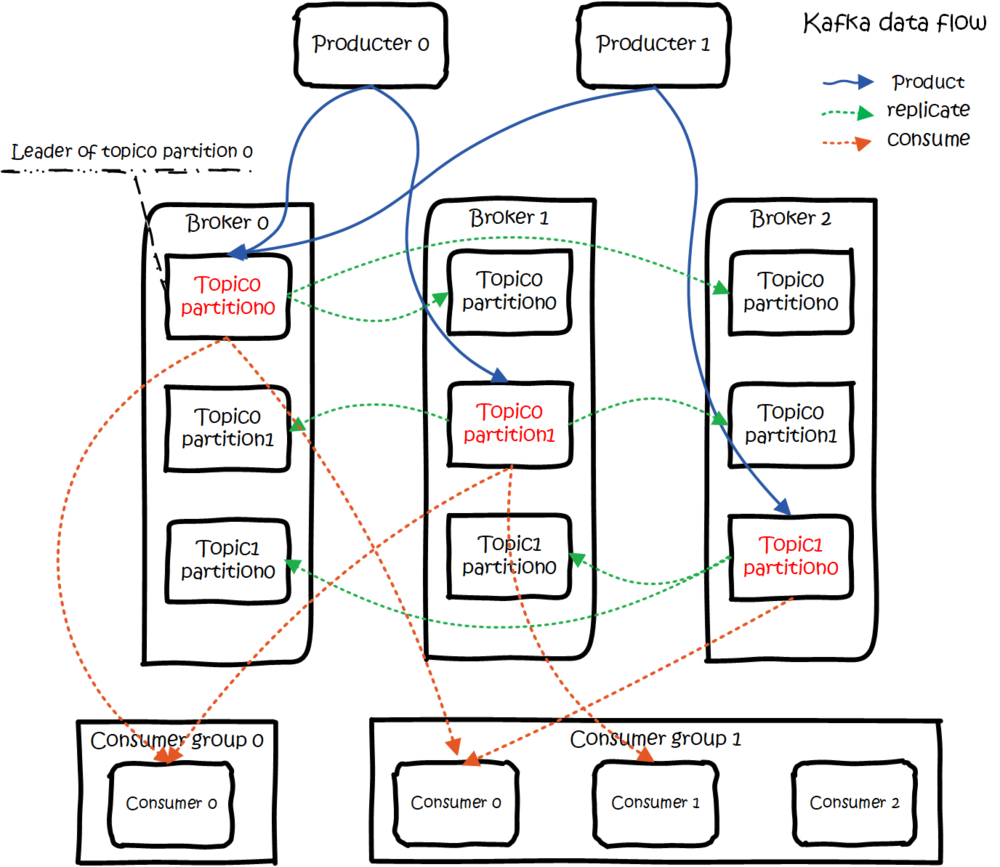
Kafka 的总体数据流是这样的:Producer 往 Broker 里面的指定 Topic 中写消息,Consumers 从 Brokers 里面拉去指定 Topic 的消息,然后进行业务处理。
图中有两个 topic,topic 0 有两个 partition,topic 1 有一个 partition ,三副本备份。可以看到consumer gourp 1 中的 consumer 2 没有分到 partition 处理,这是有可能出现的。
那么,Kafka 又是如何生产数据的?
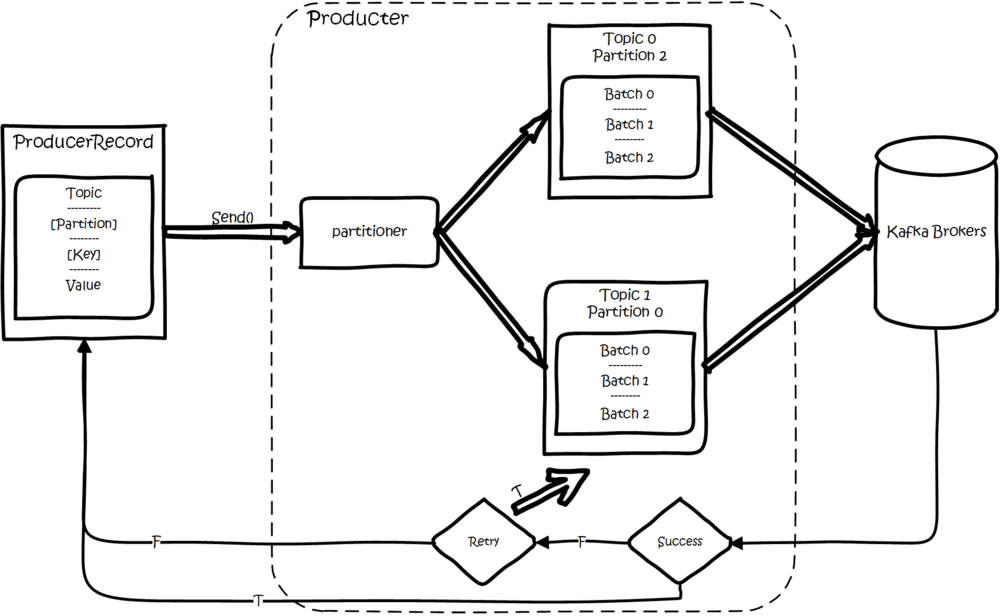
如上图所示:
- 首先创建一条记录,记录中一定要指定对应的
topic和value,key和partition可选。 - 先序列化,然后按照
topic和partition,放进对应的发送队列中。 kafka produce都是批量请求,会积攒一批,然后一起发送,不是调send()就进行立刻进行网络发包。
如果 partition 没填,那么情况会是这样的:
1.填写了 key:按照 key 进行哈希,相同 key 去一个 partition。(如果扩展了 partition 的数量那么就不能保证了)
2.没填 key:round-robin 来选 partition。
这些要发往同一个 partition 的请求按照配置,攒一波,然后由一个单独的线程一次性发过去。
六、设计原理
Kafka 的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力。
1.持久性kafka 使用文件存储消息,这就直接决定 kafka 在性能上严重依赖文件系统的本身特性.且无论任何 OS 下,对文件系统本身的优化几乎没有可能。
文件缓存/直接内存映射等是常用的手段。
因为 kafka 是对日志文件进行 append 操作,因此磁盘检索的开支是较小的。同时为了减少磁盘写入的次数,broker 会将消息暂时 buffer 起来,当消息的个数(或尺寸)达到一定阀值时,再 flush 到磁盘,这样减少了磁盘IO 调用的次数。
2.性能
需要考虑的影响性能点很多,除磁盘 IO 之外,我们还需要考虑网络 IO,这直接关系到 kafka 的吞吐量问题。kafka 并没有提供太多高超的技巧:
- 对于
producer端,可以将消息buffer起来,当消息的条数达到一定阀值时,批量发送给broker; - 对于
consumer端也是一样,批量fetch多条消息,不过消息量的大小可以通过配置文件来指定; - 对于
broker端,似乎有个sendfile系统调用可以潜在的提升网络IO的性能:将文件的数据映射到系统内存中,socket直接读取相应的内存区域即可,而无需进程再次 `copy` 和交换。
其实对于 producer/consumer/broker 三者而言,CPU 的开支应该都不大,因此启用消息压缩机制是一个良好的策略。压缩需要消耗少量的 CPU 资源,不过对于 kafka 而言,网络 IO 更应该需要考虑。可以将任何在网络上传输的消息都经过压缩。
kafka 支持 gzip/snappy 等多种压缩方式。
3.生产者
负载均衡: producer 将会和 Topic 下所有 partition leader 保持 socket 连接。消息由 producer 直接通过 socket 发送到 broker ,中间不会经过任何路由层。
事实上,消息被路由到哪个 partition 上,有 producer 客户端决定。比如可以采用random、key-hash、轮询等,如果一个 topic 中有多个 partitions,那么在 producer 端实现「消息均衡分发」是必要的。
4.消费者consumer 端向 broker 发送 fetch 请求,并告知其获取消息的 offset。此后 consumer 将会获得一定条数的消息,consumer 端也可以重置 offset 来重新消费消息。
5.消息传送机制
对于 JMS 实现,消息传输担保非常直接:有且只有一次(exactly once)。在 kafka 中稍有不同:
- at most once: 最多一次,这个和
JMS中 「非持久化」消息类似。发送一次,无论成败,将不会重发。 - at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。
- exactly once: 消息只会发送一次。
- at most once: 消费者
fetch消息,然后保存offset,然后处理消息。当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理。那么此后「未处理」的消息将不能被fetch到。 - at least once: 消费者
fetch消息,然后处理消息,然后保存offset。如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。 - exactly once:
kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的。
通常情况下「at-least-once」是我们首选。(相比「at most once」而言,重复接收数据总比丢失数据要好)。
6.复制备份kafka 将每个 partition 数据复制到多个 server 上,任何一个 partition 有一个 leader 和多个follower(可以没有),备份的个数可以通过 broker 配置文件来设定。
leader处理所有的read-write请求,follower需要和leader保持同步。follower和consumer一样,消费消息并保存在本地日志中;leader负责跟踪所有的follower状态,如果follower落后太多或者失效,leader将会把它从replicas同步列表中删除。- 当所有的
follower都将一条消息保存成功,此消息才被认为是committed,那么此时consumer才能消费它。- 即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可。(不同于其他分布式存储,比如hbase需要「多数派」存活才行) - 当
leader失效时,需在followers中选取出新的leader,可能此时follower落后于leader,因此需要选择一个up-to-date的follower。 - 选择
follower时需要兼顾一个问题,就是新leader server上所已经承载的partition leader的个数,如果一个server上有过多的partition leader,意味着此server将承受着更多的IO压力。 - 在选举新
leader,需要考虑到负载均衡。
7.日志
日志文件中保存了一序列 log entries(日志条目),每个 log entry 格式为「4个字节的数字N表示消息的长度」 + 「N个字节的消息内容」;
每个日志都有一个 offset 来唯一的标记一条消息,offset 的值为 8 个字节的数字,表示此消息在此 partition 中所处的起始位置。
每个 partition 在物理存储层面,有多个 log file 组成(称为 segment)。segmentfile 的命名为 “最小offset”.kafka
8.分配kafka 使用 zookeeper 来存储一些 meta 信息,并使用了 zookeeper watch 机制来发现 meta 信息的变更并作出相应的动作(比如 consumer 失效,触发负载均衡等)
更多细节,请移步 Kafka 入门。
七、快速开始
1.下载 kafka
2.解压并进入目录1
2tar -xzf kafka_2.11-2.0.0.tgz
cd kafka_2.11-2.0.0
3.启动服务kafka 使用了 zooKeeper,所以我们需要先启动 zooKeeper 服务。执行:1
bin/zookeeper-server-start.sh config/zookeeper.properties
然后,再启动 kafka 服务:1
bin/kafka-server-start.sh config/server.properties
控制台应该会输出:1
2...
[2018-10-27 14:41:16,579] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
…
突然发现要运行一个简单的 Demo 还需要做很多事情,鉴于文章内容过长。我将会在下一篇文章:快速上手 Kafka中详细说明,还请各位移步。
